AI
大模型RAG简介
Langchain简介
ollama安装指南
OpenAI Key
提示词
Huggingface 下载GGUF大模型的方法
使用说明
本文档使用 MrDoc 发布
-
+
首页
大模型RAG简介
# 写在前面 > 大模型(Large Language Model,LLM)的浪潮已经席卷了几乎各行业,但当涉及到专业场景或行业细分领域时,通用大模型就会面临专业知识不足的问题。相对于成本昂贵的“Post Train”或“SFT”,基于RAG的技术方案往往成为一种更优选择。本文从RAG架构入手,详细介绍相关技术细节,并附上一份实践案例。 ### 什么是RAG? 检索增强生成(Retrieval Augmented Generation),简称 RAG,已经成为当前最火热的LLM应用方案。经历今年年初那一波大模型潮,想必大家对大模型的能力有了一定的了解,但是当我们将大模型应用于实际业务场景时会发现,通用的基础大模型基本无法满足我们的实际业务需求,主要有以下几方面原因: - **知识的局限性**:模型自身的知识完全源于它的训练数据,而现有的主流大模型(ChatGPT、文心一言、通义千问…)的训练集基本都是构建于网络公开的数据,对于一些实时性的、非公开的或离线的数据是无法获取到的,这部分知识也就无从具备。 - **幻觉问题**:所有的AI模型的底层原理都是基于数学概率,其模型输出实质上是一系列数值运算,大模型也不例外,所以它有时候会一本正经地胡说八道,尤其是在大模型自身不具备某一方面的知识或不擅长的场景。而这种幻觉问题的区分是比较困难的,因为它要求使用者自身具备相应领域的知识。 - **数据安全性**:对于企业来说,数据安全至关重要,没有企业愿意承担数据泄露的风险,将自身的私域数据上传第三方平台进行训练。这也导致完全依赖通用大模型自身能力的应用方案不得不在数据安全和效果方面进行取舍。 而RAG是解决上述问题的一套有效方案。 ### RAG架构 RAG的架构如图中所示,简单来讲,RAG就是通过检索获取相关的知识并将其融入Prompt,让大模型能够参考相应的知识从而给出合理回答。因此,可以将RAG的核心理解为“检索+生成”,前者主要是利用向量数据库的高效存储和检索能力,召回目标知识;后者则是利用大模型和Prompt工程,将召回的知识合理利用,生成目标答案。 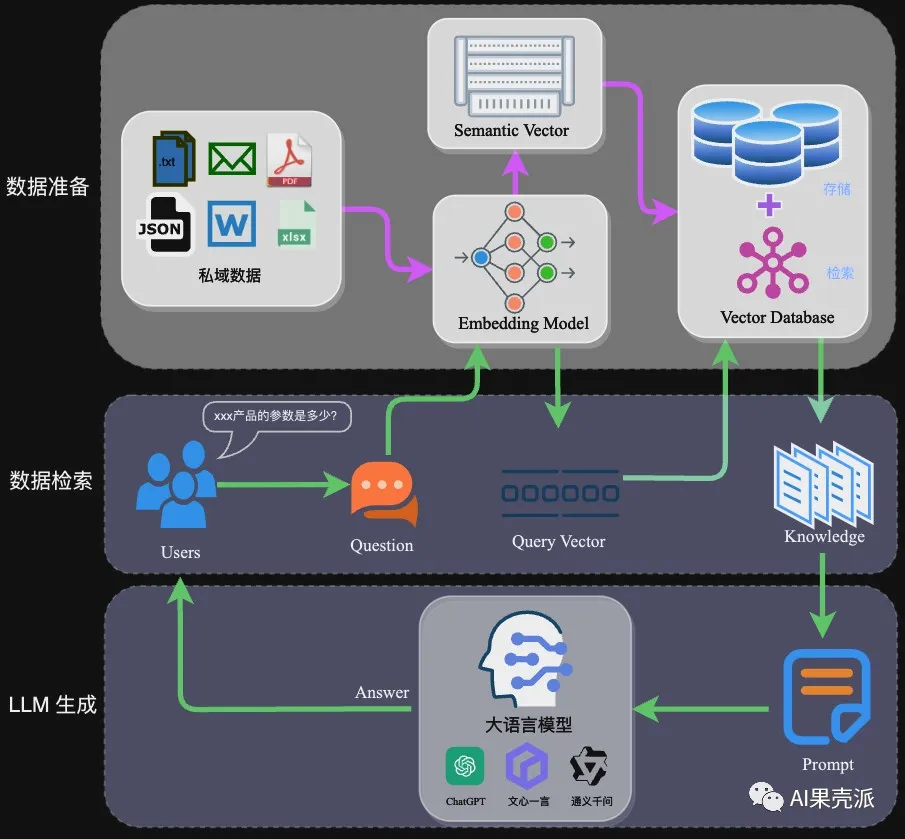 完整的RAG应用流程主要包含两个阶段: - 数据准备阶段:数据提取——>文本分割——>向量化(embedding)——>数据入库 - 应用阶段:用户提问——>数据检索(召回)——>注入Prompt——>LLM生成答案 下面我们详细介绍一下各环节的技术细节和注意事项: **数据准备阶段**: 数据准备一般是一个离线的过程,主要是将私域数据向量化后构建索引并存入数据库的过程。主要包括:数据提取、文本分割、向量化、数据入库等环节。 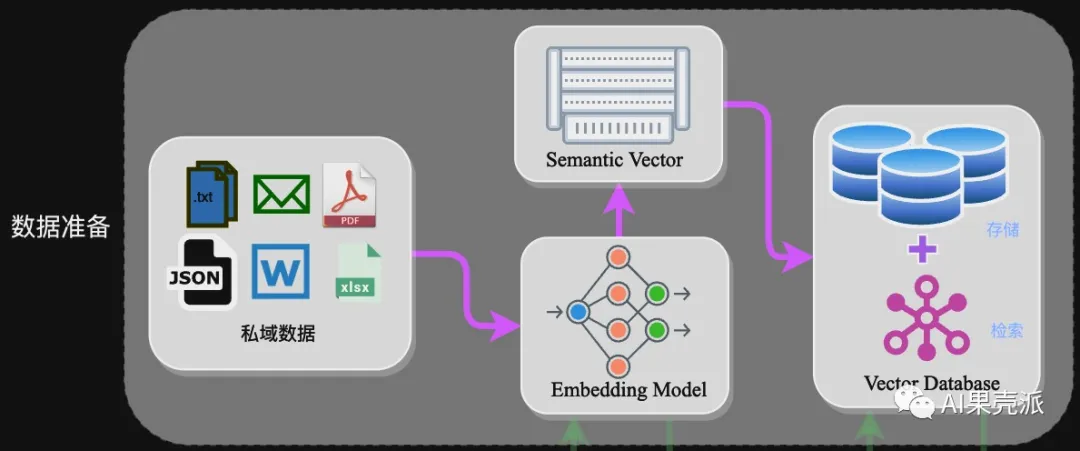 - **数据提取** - 数据加载:包括多格式数据加载、不同数据源获取等,根据数据自身情况,将数据处理为同一个范式。 - 数据处理:包括数据过滤、压缩、格式化等。 - 元数据获取:提取数据中关键信息,例如文件名、Title、时间等 。 - **文本分割**: 文本分割主要考虑两个因素: 1. embedding模型的Tokens限制情况; 2. 语义完整性对整体的检索效果的影响。一些常见的文本分割方式如下: - 句分割:以”句”的粒度进行切分,保留一个句子的完整语义。常见切分符包括:句号、感叹号、问号、换行符等。 - 固定长度分割:根据embedding模型的token长度限制,将文本分割为固定长度(例如256/512个tokens),这种切分方式会损失很多语义信息,一般通过在头尾增加一定冗余量来缓解。 - **向量化(embedding)**: 向量化是一个将文本数据转化为向量矩阵的过程,该过程会直接影响到后续检索的效果。目前常见的embedding模型如表中所示,这些embedding模型基本能满足大部分需求,但对于特殊场景(例如涉及一些罕见专有词或字等)或者想进一步优化效果,则可以选择开源Embedding模型微调或直接训练适合自己场景的Embedding模型。 | 模型名称 | 描述 | 获取地址 | | --- | --- | --- | | ChatGPT-Embedding | ChatGPT-Embedding由OpenAI公司提供,以接口形式调用。 | https://platform.openai.com/docs/guides/embeddings/what-are-embeddings | | ERNIE-Embedding V1 | ERNIE-Embedding V1由百度公司提供,依赖于文心大模型能力,以接口形式调用。 | https://cloud.baidu.com/doc/WENXINWORKSHOP/s/alj562vvu | | M3E | M3E是一款功能强大的开源Embedding模型,包含m3e-small、m3e-base、m3e-large等多个版本,支持微调和本地部署。 | https://huggingface.co/moka-ai/m3e-base | | BGE | BGE由北京智源人工智能研究院发布,同样是一款功能强大的开源Embedding模型,包含了支持中文和英文的多个版本,同样支持微调和本地部署。 | https://huggingface.co/BAAI/bge-base-en-v1.5 | - **数据入库:** 数据向量化后构建索引,并写入数据库的过程可以概述为数据入库过程,适用于RAG场景的数据库包括:FAISS、Chromadb、ES、milvus等。一般可以根据业务场景、硬件、性能需求等多因素综合考虑,选择合适的数据库。 **应用阶段:** 在应用阶段,我们根据用户的提问,通过高效的检索方法,召回与提问最相关的知识,并融入Prompt;大模型参考当前提问和相关知识,生成相应的答案。关键环节包括:数据检索、注入Prompt等。 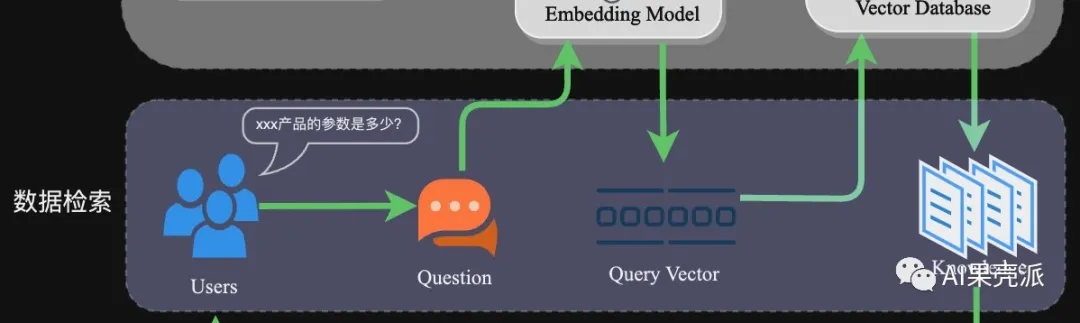 - **数据检索** 常见的数据检索方法包括:相似性检索、全文检索等,根据检索效果,一般可以选择多种检索方式融合,提升召回率。 - 相似性检索:即计算查询向量与所有存储向量的相似性得分,返回得分高的记录。常见的相似性计算方法包括:余弦相似性、欧氏距离、曼哈顿距离等。 - 全文检索:全文检索是一种比较经典的检索方式,在数据存入时,通过关键词构建倒排索引;在检索时,通过关键词进行全文检索,找到对应的记录。 - **注入Prompt** 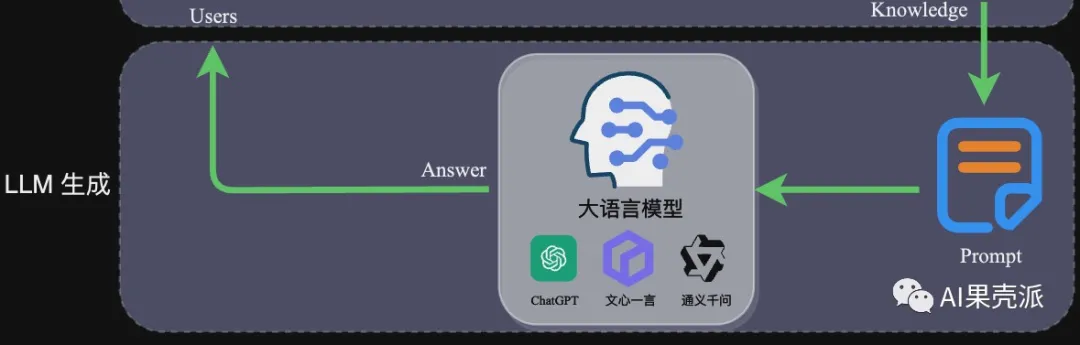 Prompt作为大模型的直接输入,是影响模型输出准确率的关键因素之一。在RAG场景中,Prompt一般包括任务描述、背景知识(检索得到)、任务指令(一般是用户提问)等,根据任务场景和大模型性能,也可以在Prompt中适当加入其他指令优化大模型的输出。一个简单知识问答场景的Prompt如下所示: ``` 【任务描述】假如你是一个专业的客服机器人,请参考【背景知识】,回 【背景知识】{content} // 数据检索得到的相关文本 【问题】石头扫地机器人P10的续航时间是多久? ``` Prompt的设计只有方法、没有语法,比较依赖于个人经验,在实际应用过程中,往往需要根据大模型的实际输出进行针对性的Prompt调优。 ### 实践案例——私域知识问答应用案例 本次选用百度百科——藜麦数据(https://baike.baidu.com/item/藜麦/5843874 模拟个人或企业私域数据,并基于langchain开发框架,实现一种简单的RAG问答应用示例。 - **环境准备** 安装相关依赖 ``` # 环境准备,安装相关依赖 pip install datasets langchain sentence_transformers tqdm chromadb langchain_wenxin ``` - ****本地数据加载**** ``` from langchain.document_loaders import TextLoader loader = TextLoader("./藜.txt") documents = loader.load() ``` ``` [Document(page_content='藜(读音lí)麦(Chenopodium\xa0quinoa\xa0Willd.)是藜科藜属植物。穗部可呈红、紫、黄,植株形状类似灰灰菜,成熟后穗部类似高粱穗。植株大小受环境及遗传因素影响较大,从0.3-3米不等,茎部质地较硬,可分枝可不分。单叶互生,叶片呈鸭掌状,叶缘分为全缘型与锯齿缘型。藜麦花两性,花序呈伞状、穗状、圆锥状,藜麦种子较小,呈小圆药片状,直径1.5-2毫米,千粒重1.4-3克。\xa0[1]\xa0\n原产于南美洲安第斯山脉的哥伦比亚、厄瓜多尔、秘鲁等中高海拔山区。具有一定的耐旱、耐寒、耐盐性,生长范围约为海平面到海拔4500米左右的高原上,最适的高度为海拔3000-4000米的高原或山地地区。\xa0[1]\xa0\n藜麦富含的维生素、多酚、类黄酮类、皂苷和植物甾醇类物质具有多种健康功效。 ``` - **文档分割** 文档分割,借助langchain的字符分割器,这里采用固定字符长度分割chunk_size=128 ``` # 文档分割 from langchain.text_splitter import CharacterTextSplitter # 创建拆分器 text_splitter = CharacterTextSplitter(chunk_size=128, chunk_overlap=0) # 拆分文档 documents = text_splitter.split_documents(documents) ``` ``` [Document(page_content='藜(读音lí)麦(Chenopodium\xa0quinoa\xa0Willd.)是藜科藜属植物。穗部可呈红、紫、黄,植株形状类似灰灰菜,成熟后穗部类似高粱穗。植株大小受环境及遗传因素影响较大,从0.3-3米不等,茎部质地较硬,可分枝可不分。单叶互生,叶片呈鸭掌状,叶缘分为全缘型与锯齿缘型。藜麦花两性,花序呈伞状、穗状、圆锥状,藜麦种子较小,呈小圆药片状,直径1.5-2毫米,千粒重1.4-3克。\xa0[1]\xa0\n原产于南美洲安第斯山脉的哥伦比亚、厄瓜多尔、秘鲁等中高海拔山区。具有一定的耐旱、耐寒、耐盐性,生长范围约为海平面到海拔4500米左右的高原上,最适的高度为海拔3000-4000米的高原或山地地区。\xa0[1]\xa0\n藜麦富含的维生素、多酚、类黄酮类、皂苷和植物甾醇类物质具有多种健康功效。藜麦具有高蛋白,其所含脂肪中不饱和脂肪酸占83%,还是一种低果糖低葡萄糖的食物,能在糖脂代谢过程中发挥有益功效。\xa0[1]\xa0\xa0[5]\xa0\n国内藜麦产品的销售以电商为主,缺乏实体店销售,藜麦市场有待进一步完善。藜麦国际市场需求强劲,发展前景十分广阔。通过加快品种培育和生产加工设备研发,丰富产品种类,藜麦必将在“调结构,转方式,保增收”的农业政策落实中发挥重要作用。\xa0[5]\xa0\n2022年5月,“超级谷物”藜麦在宁洱县试种成功。', metadata={'source': './藜.txt'}), Document(page_content='藜麦是印第安人的传统主食,几乎和水稻同时被驯服有着6000多年的种植和食用历史。藜麦具有相当全面营养成分,并且藜麦的口感口味都容易被人接受。在藜麦这种营养丰富的粮食滋养下南美洲的印第安人创造了伟大的印加文明,印加人将藜麦尊为粮食之母。美国人早在80年代就将藜麦引入NASA,作为宇航员的日常口粮,FAO认定藜麦是唯一一种单作物即可满足人类所需的全部营养的粮食,并进行藜麦的推广和宣传。2013年是联合国钦定的国际藜麦年。以此呼吁人们注意粮食安全和营养均衡。', metadata={'source': './藜.txt'}), Document(page_content='藜麦穗部可呈红、紫、黄,植株形状类似灰灰菜,成熟后穗部类似高粱穗。植株大小受环境及遗传因素影响较大,从0.3-3米不等,茎部质地较硬,可分枝可不分。单叶互生,叶片呈鸭掌状,叶缘分为全缘型与锯齿缘型。根系庞大但分布较浅,根上的须根多,吸水能力强。藜麦花两性,花序呈伞状、穗状、圆锥状,藜麦种子较小,呈小圆药片状,直径1.5-2毫米,千粒重1.4-3克。', metadata={'source': './藜.txt'}), Document(page_content='原产于南美洲安第斯山脉的哥伦比亚、厄瓜多尔、秘鲁等中高海拔山区。具有一定的耐旱、耐寒、耐盐性,生长范围约为海平面到海拔4500米左右的高原上,最适的高度为海拔3000-4000米的高原或山地地区。\n\n播前准备', metadata={'source': './藜.txt'}), Document(page_content='繁殖\n地块选择:应选择地势较高、阳光充足、通风条件好及肥力较好的地块种植。藜麦不宜重茬,忌连作,应合理轮作倒茬。前茬以大豆、薯类最好,其次是玉米、高粱等。\xa0[4]\xa0\n施肥整地:早春土壤刚解冻,趁气温尚低、土壤水分蒸发慢的时候,施足底肥,达到土肥融合,壮伐蓄水。播种前每降1次雨及时耙耱1次,做到上虚下实,干旱时只耙不耕,并进行压实处理。一般每亩(667平方米/亩,下同)施腐熟农家肥1000-2000千克、硫酸钾型复合肥20-30千克。如果土壤比较贫瘠,可适当增加复合肥的施用量。\xa0[4]', metadata={'source': './藜.txt'}), ...] ``` - **向量化&数据入库** 接下来对分割后的数据进行embedding,并写入数据库。这里选用 m3e-base作为embedding模型,向量数据库选用Chroma ``` from langchain.embeddings import HuggingFaceBgeEmbeddings from langchain.vectorstores import Chroma # embedding model: m3e-base model_name = "moka-ai/m3e-base" model_kwargs = {'device': 'cpu'} encode_kwargs = {'normalize_embeddings': True embedding = HuggingFaceBgeEmbeddings( model_name=model_name, model_kwargs=model_kwargs, encode_kwargs=encode_kwargs, query_instruction="为文本生成向量表示用于文本检索" ) # load data to Chroma db db = Chroma.from_documents(documents, embedding) # similarity search db.similarity_search("藜一般在几月播种?") ``` - **Prompt设计** prompt设计,这里只是一个prompt的简单示意,在实际业务场景中需要针对场景特点针对性调优。 ``` template = ''' 【任务描述】 请根据用户输入的上下文回答问题,并遵守回答要求。 【背景知识】 {{context}} 【回答要求】 - 你需要严格根据背景知识的内容回答,禁止根据常识和已知信息回答问题。 - 对于不知道的信息,直接回答“未找到相关答案” ----------- {question} ''' ``` - **RetrievalqaChain构建** 这里采用ConversationalRetrievalChain,ConversationalRetrievalQA chain 是建立在 RetrievalQAChain 之上,提供历史聊天记录组件。如下面定义了memory来追踪聊天记录,在流程上,先将历史问题和当前输入问题融合为一个新的独立问题,然后再进行检索,获取问题相关知识,最后将获取的知识和生成的新问题注入Prompt让大模型生成回答。 ``` from langchain import LLMChain from langchain_wenxin.llms import Wenxin from langchain.prompts import PromptTemplate from langchain.memory import ConversationBufferMemory from langchain.chains import ConversationalRetrievalChain from langchain.prompts.chat import ChatPromptTemplate, SystemMessagePromptTemplate, HumanMessagePromptTemplate # LLM选型 llm = Wenxin(model="ernie-bot", baidu_api_key="baidu_api_key", baidu_secret_key="baidu_secret_key") retriever = db.as_retriever() memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True) qa = ConversationalRetrievalChain.from_llm(llm, retriever, memory=memory) qa({"question": "藜怎么防治虫害?"}) ``` ``` {'question': '藜怎么防治虫害?', 'chat_history': [HumanMessage(content='藜怎么防治虫害?'), AIMessage(content='藜麦常见虫害有象甲虫、金针虫、蝼蛄、黄条跳甲、横纹菜蝽、萹蓄齿胫叶甲、潜叶蝇、蚜虫、夜蛾等。防治方法:可每亩用3%的辛硫磷颗粒剂2-2.5千克于耕地前均匀撒施,随耕地翻入土中。也可以每亩用40%的辛硫磷乳油250毫升,加水1-2千克,拌细土20-25千克配成毒土,撒施地面翻入土中,防治地下害虫。')], 'answer': '藜麦常见虫害有象甲虫、金针虫、蝼蛄、黄条跳甲、横纹菜蝽、萹蓄齿胫叶甲、潜叶蝇、蚜虫、夜蛾等。防治方法:可每亩用3%的辛硫磷颗粒剂2-2.5千克于耕地前均匀撒施,随耕地翻入土中。也可以每亩用40%的辛硫磷乳油250毫升,加水1-2千克,拌细土20-25千克配成毒土,撒施地面翻入土中,防治地下害虫。'} ``` - **高级用法** 针对多轮对话场景,增加question\_generator对历史对话记录进行压缩生成新的question,增加combine\_docs\_chain对检索得到的文本进一步融合 ```python from langchain import LLMChain from langchain.prompts import PromptTemplate from langchain.memory import ConversationBufferMemory from langchain.chains import ConversationalRetrievalChain, StuffDocumentsChain from langchain.chains.qa_with_sources import load_qa_with_sources_chain from langchain.prompts.chat import ChatPromptTemplate from langchain.prompts.chat import SystemMessagePromptTemplate,HumanMessagePromptTemplate # 构建初始 messages 列表,这里可以理解为是 openai 传入的 messages 参数 messages = [ SystemMessagePromptTemplate.from_template(qa_template), HumanMessagePromptTemplate.from_template('{question}') ] # 初始化 prompt 对象 prompt = ChatPromptTemplate.from_messages(messages) llm_chain = LLMChain(llm=llm, prompt=prompt) combine_docs_chain = StuffDocumentsChain( llm_chain=llm_chain, document_separator="\n\n", document_variable_name="context",) q_gen_chain = LLMChain(llm=llm, prompt=PromptTemplate.from_template(qa_condense_template)) qa = ConversationalRetrievalChain( combine_docs_chain=combine_docs_chain, question_generator=q_gen_chain, return_source_documents=True, return_generated_question=True, retriever=retriever ) print(qa({'question': "藜麦怎么防治虫害?", "chat_history": []})) ``` ```python {'question': '藜怎么防治虫害?', 'chat_history': [], 'answer': '根据背景知识,藜麦常见虫害有象甲虫、金针虫、蝼蛄、黄条跳甲、横纹菜蝽、萹蓄齿胫叶甲、潜叶蝇、蚜虫、夜蛾等。防治方法如下:\n\n1. 可每亩用3%的辛硫磷颗粒剂2-2.5千克于耕地前均匀撒施,随耕地翻入土中。\n2. 也可以每亩用40%的辛硫磷乳油250毫升,加水1-2千克,拌细土20-25千克配成毒土,撒施地面翻入土中,防治地下害虫。\n\n以上内容仅供参考,如果需要更多信息,可以阅读农业相关书籍或请教农业专家。', 'source_documents': [ Document(page_content='病害:主要防治叶斑病,使用12.5%的烯唑醇可湿性粉剂3000-4000倍液喷雾防治,一般防治1-2次即可收到效果。\xa0[4]\xa0\n虫害:藜麦常见虫害有象甲虫、金针虫、蝼蛄、黄条跳甲、横纹菜蝽、萹蓄齿胫叶甲、潜叶蝇、蚜虫、夜蛾等。防治方法:可每亩用3%的辛硫磷颗粒剂2-2.5千克于耕地前均匀撒施,随耕地翻入土中。也可以每亩用40%的辛硫磷乳油250毫升,加水1-2千克,拌细土20-25千克配成毒土,撒施地面翻入土中,防治地下害虫', metadata={'source': './藜.txt'}), Document(page_content='中期管理\n在藜麦8叶龄时,将行中杂草、病株及残株拔掉,提高整齐度,增加通风透光,同时,进行根部培土,防止后期倒伏。\xa0[4]', metadata={'source': './藜.txt'})], 'generated_question': '藜怎么防治虫害?'} ```
admin
2024年10月15日 09:48
转发文档
收藏文档
上一篇
下一篇
手机扫码
复制链接
手机扫一扫转发分享
复制链接
Markdown文件
分享
链接
类型
密码
更新密码