AI
大模型RAG简介
Langchain简介
ollama安装指南
OpenAI Key
提示词
Huggingface 下载GGUF大模型的方法
使用说明
本文档使用 MrDoc 发布
-
+
首页
Huggingface 下载GGUF大模型的方法
## 前言 以qwen2.5-72b-instruct-q3_k_m大模型为例,演示解决ollama pull hf.co/Qwen/Qwen2.5-72B-Instruct-GGUF:Q3_k_M ## 必备条件 需要翻墙 ## 使用ollama pull下载出错 ```shell sam@sam-pn64:/diskA/docker/temp2$ export all_proxy='http://127.0.0.1:7890' sam@sam-pn64:/diskA/docker/temp2$ ollama pull hf.co/Qwen/Qwen2.5-72B-Instruct-GGUF:Q3_k_M pulling manifest Error: pull model manifest: Get "https://huggingface.co/v2/Qwen/Qwen2.5-72B-Instruct-GGUF/manifests/Q3_k_M": dial tcp 185.60.219.41:443: i/o timeout ``` 可以看到出错了,然后给了你一个URL地址`https://huggingface.co/v2/Qwen/Qwen2.5-72B-Instruct-GGUF/manifests/Q3_k_M` 打开看一下 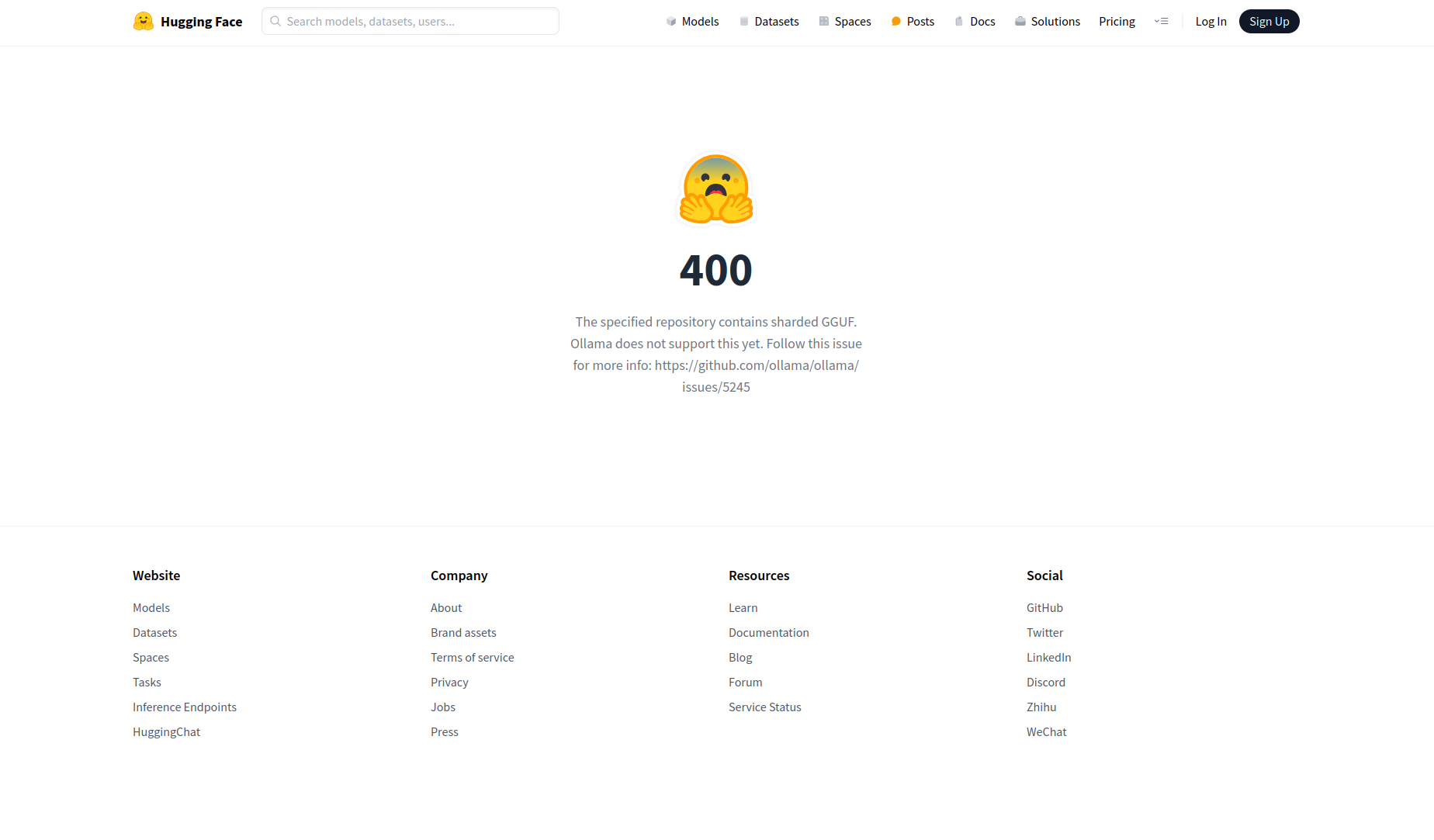 可以看到让参考:https://github.com/ollama/ollama/issues/5245 打开看看 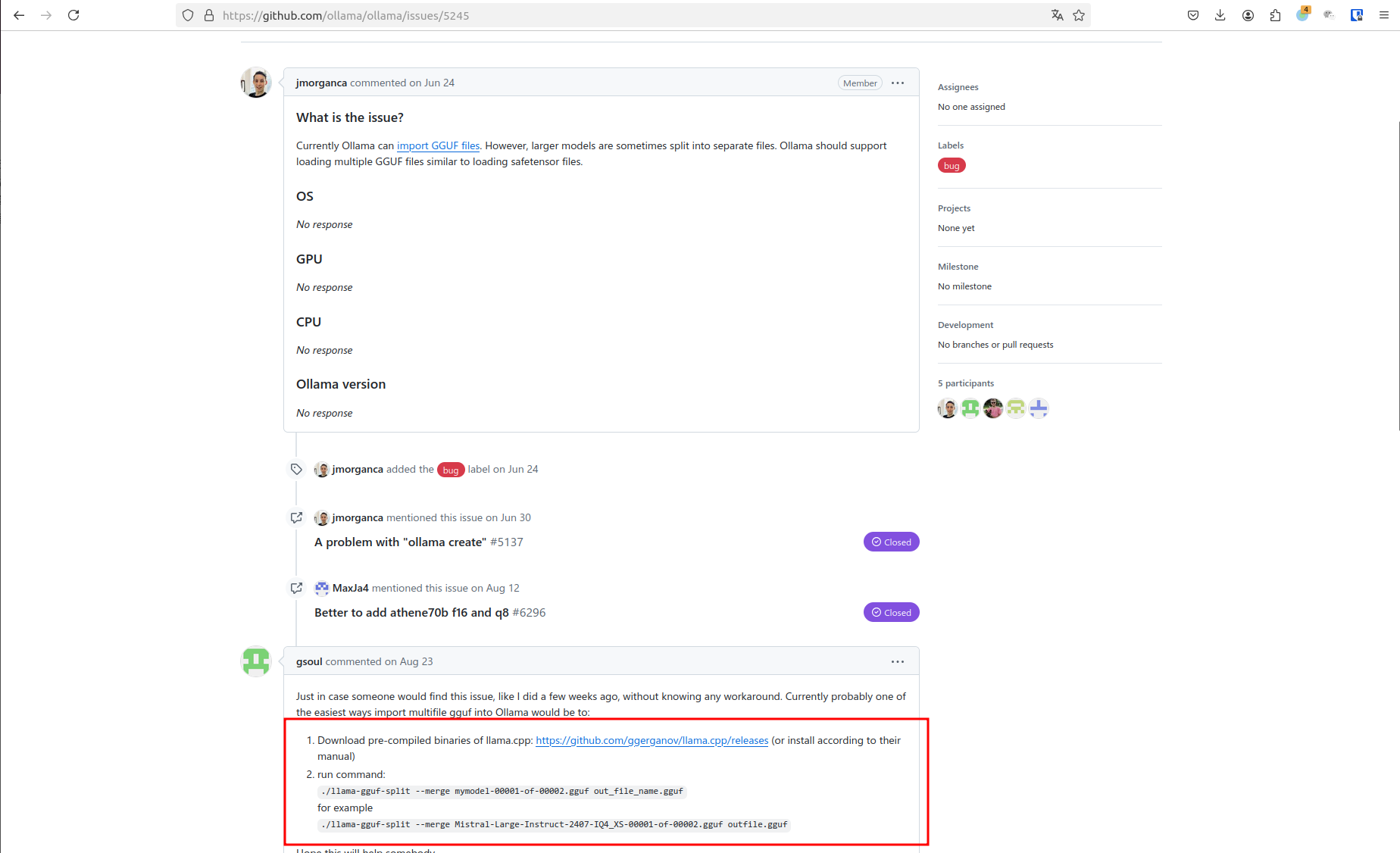 很明显,需要下载个工具,然后做merge 那首先我们要去的这些分卷的文件 我先取Hugging Face上用git clone下载这个仓库 git clone https://huggingface.co/Qwen/Qwen2.5-72B-Instruct-GGUF 这个地址是凑巧找到的,因为要GGUF文件嘛,我在hf上只找到了git clone https://huggingface.co/Qwen/Qwen2.5-72B-Instruct 抱着试试看的心态,就下了git clone https://huggingface.co/Qwen/Qwen2.5-72B-Instruct-GGUF 然后ls看一下 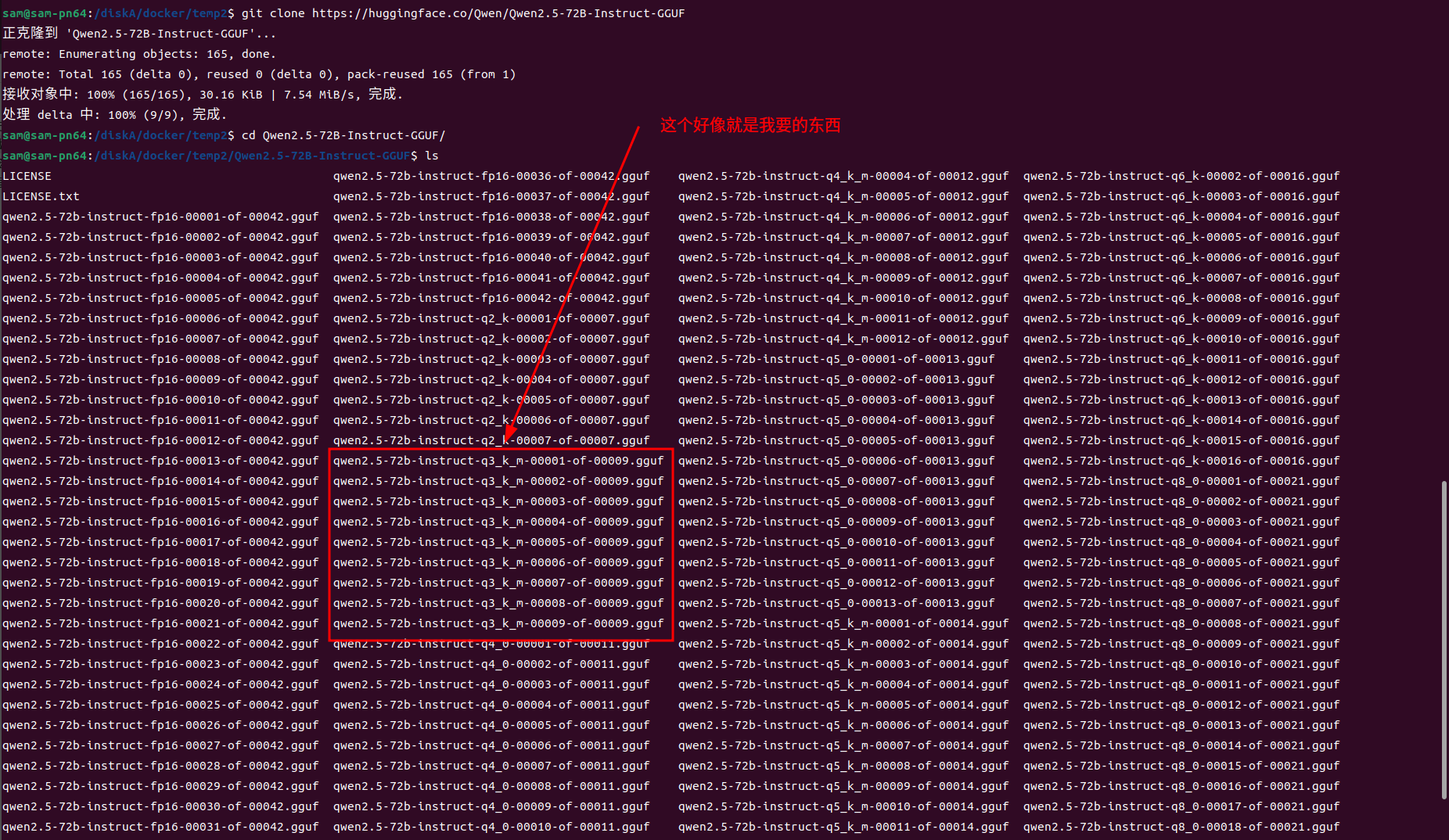 里面好像就有我要的东西,但是文件大小不对啊,模型没有这么小的 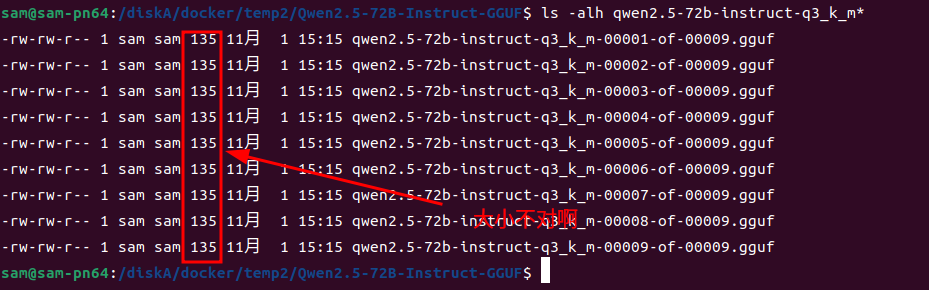 于是看了下文件夹中的`README.MD` --- license: other license_name: qwen license_link: https://huggingface.co/Qwen/Qwen2.5-72B-Instruct-GGUF/blob/main/LICENSE language: - en pipeline_tag: text-generation base_model: Qwen/Qwen2.5-72B-Instruct tags: - chat --- # Qwen2.5-72B-Instruct-GGUF ## Introduction Qwen2.5 is the latest series of Qwen large language models. For Qwen2.5, we release a number of base language models and instruction-tuned language models ranging from 0.5 to 72 billion parameters. Qwen2.5 brings the following improvements upon Qwen2: - Significantly **more knowledge** and has greatly improved capabilities in **coding** and **mathematics**, thanks to our specialized expert models in these domains. - Significant improvements in **instruction following**, **generating long texts** (over 8K tokens), **understanding structured data** (e.g, tables), and **generating structured outputs** especially JSON. **More resilient to the diversity of system prompts**, enhancing role-play implementation and condition-setting for chatbots. - **Long-context Support** up to 128K tokens and can generate up to 8K tokens. - **Multilingual support** for over 29 languages, including Chinese, English, French, Spanish, Portuguese, German, Italian, Russian, Japanese, Korean, Vietnamese, Thai, Arabic, and more. **This repo contains the instruction-tuned 72B Qwen2.5 model in the GGUF Format**, which has the following features: - Type: Causal Language Models - Training Stage: Pretraining & Post-training - Architecture: transformers with RoPE, SwiGLU, RMSNorm, and Attention QKV bias - Number of Parameters: 72.7B - Number of Paramaters (Non-Embedding): 70.0B - Number of Layers: 80 - Number of Attention Heads (GQA): 64 for Q and 8 for KV - Context Length: Full 32,768 tokens and generation 8192 tokens - Note: Currently, only vLLM supports YARN for length extrapolating. If you want to process sequences up to 131,072 tokens, please refer to non-GGUF models. - Quantization: q2_K, q3_K_M, q4_0, q4_K_M, q5_0, q5_K_M, q6_K, q8_0 For more details, please refer to our [blog](https://qwenlm.github.io/blog/qwen2.5/), [GitHub](https://github.com/QwenLM/Qwen2.5), and [Documentation](https://qwen.readthedocs.io/en/latest/). ## Quickstart Check out our [llama.cpp documentation](https://qwen.readthedocs.io/en/latest/run_locally/llama.cpp.html) for more usage guide. We advise you to clone [`llama.cpp`](https://github.com/ggerganov/llama.cpp) and install it following the official guide. We follow the latest version of llama.cpp. In the following demonstration, we assume that you are running commands under the repository `llama.cpp`. Since cloning the entire repo may be inefficient, you can manually download the GGUF file that you need or use `huggingface-cli`: 1. Install ```shell pip install -U huggingface_hub ``` 2. Download: ```shell huggingface-cli download Qwen/Qwen2.5-72B-Instruct-GGUF --include "qwen2.5-72b-instruct-q5_k_m*.gguf" --local-dir . --local-dir-use-symlinks False ``` For large files, we split them into multiple segments due to the limitation of file upload. They share a prefix, with a suffix indicating its index. For examples, `qwen2.5-72b-instruct-q5_k_m-00001-of-00014.gguf` to `qwen2.5-72b-instruct-q5_k_m-00014-of-00014.gguf`. The above command will download all of them. 3. (Optional) Merge: For split files, you need to merge them first with the command `llama-gguf-split` as shown below: ```bash # ./llama-gguf-split --merge <first-split-file-path> <merged-file-path> ./llama-gguf-split --merge qwen2.5-72b-instruct-q5_k_m-00001-of-00014.gguf qwen2.5-72b-instruct-q5_k_m.gguf ``` For users, to achieve chatbot-like experience, it is recommended to commence in the conversation mode: ```shell ./llama-cli -m <gguf-file-path> \ -co -cnv -p "You are Qwen, created by Alibaba Cloud. You are a helpful assistant." \ -fa -ngl 80 -n 512 ``` ## Evaluation & Performance Detailed evaluation results are reported in this [📑 blog](https://qwenlm.github.io/blog/qwen2.5/). For quantized models, the benchmark results against the original bfloat16 models can be found [here](https://qwen.readthedocs.io/en/latest/benchmark/quantization_benchmark.html) For requirements on GPU memory and the respective throughput, see results [here](https://qwen.readthedocs.io/en/latest/benchmark/speed_benchmark.html). ## Citation If you find our work helpful, feel free to give us a cite. ``` @misc{qwen2.5, title = {Qwen2.5: A Party of Foundation Models}, url = {https://qwenlm.github.io/blog/qwen2.5/}, author = {Qwen Team}, month = {September}, year = {2024} } @article{qwen2, title={Qwen2 Technical Report}, author={An Yang and Baosong Yang and Binyuan Hui and Bo Zheng and Bowen Yu and Chang Zhou and Chengpeng Li and Chengyuan Li and Dayiheng Liu and Fei Huang and Guanting Dong and Haoran Wei and Huan Lin and Jialong Tang and Jialin Wang and Jian Yang and Jianhong Tu and Jianwei Zhang and Jianxin Ma and Jin Xu and Jingren Zhou and Jinze Bai and Jinzheng He and Junyang Lin and Kai Dang and Keming Lu and Keqin Chen and Kexin Yang and Mei Li and Mingfeng Xue and Na Ni and Pei Zhang and Peng Wang and Ru Peng and Rui Men and Ruize Gao and Runji Lin and Shijie Wang and Shuai Bai and Sinan Tan and Tianhang Zhu and Tianhao Li and Tianyu Liu and Wenbin Ge and Xiaodong Deng and Xiaohuan Zhou and Xingzhang Ren and Xinyu Zhang and Xipin Wei and Xuancheng Ren and Yang Fan and Yang Yao and Yichang Zhang and Yu Wan and Yunfei Chu and Yuqiong Liu and Zeyu Cui and Zhenru Zhang and Zhihao Fan}, journal={arXiv preprint arXiv:2407.10671}, year={2024} } ``` 发现只要做完Quick Start中的1, 2, 3就可以了。
admin
2024年11月1日 15:24
转发文档
收藏文档
上一篇
下一篇
手机扫码
复制链接
手机扫一扫转发分享
复制链接
Markdown文件
分享
链接
类型
密码
更新密码